PostgreSQL的事务隔离和MVCC
因为之前遇到的并发问题,所以又把pg的事务隔离和mvcc实现温习了一遍,稍微整理,遂有此文。
数据库并发问题
说到事务隔离,得先说说数据库可能产生的几种并发问题:
- 脏读(Dirty Read):一个事务a读到了事务b更新未提交的数据,b回滚了,a读到的数据就是脏数据
- 不可重复读(NonRepeatable Read):事务a多次读取同一个数据,事务b在a多次读取的过程中,对这条数据做出了更改并提交,导致事务a在多次读取结果不一致
- 幻读(Phantom Read):事务a在批量更新一个表,事务b这个时候插入了一条不同的记录,导致事务a在改完后发现还有一条记录没有改,就像幻觉一样
不可重复读和幻读很容易混淆,其实幻读是不可重复读的一种特殊情况,只不过不可重复读侧重于修改,幻读侧重于新增或删除,解决不可重复读的问题只需要锁住满足条件的行,解决幻读需要提高事务的隔离级别,但与此同时,事务的隔离级别越高,并发能力也就越低。所以,所以还需要权衡。
事务隔离级别
为了有效保证并发读取数据的正确性,提出的事务隔离级别:
- 未提交读(Read Uncommitted):允许脏读,也就是可能读取到其他事务中未提交的修改
- 提交读(Read Committed):只能读取到其他事务已经提交的数据。PostgreSQL、Oracle等多数数据库默认都是该级别
- 可重复读(Repeated Read):可重复读。在同一个事务内的查询都是事务开始时刻一致的,InnoDB默认级别。
- 串行读(Serializable):完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞
在SQL标准中,定义了不同隔离级别会出现的并发问题:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未提交读 | 可能 | 可能 | 可能 |
| 已提交读 | 不可能 | 可能 | 可能 |
| 可重复读 | 不可能 | 不可能 | 可能 |
| 串行读 | 不可能 | 不可能 | 不可能 |
注意,这是ANSI SQL标准中的定义,但是具体到数据库的实现可能不一样,只会更严格。比如Read Uncommitted这种隔离级别,其实在实际使用中是没有意义的,设置这种级别还不如用Nosql,所以在pg 中其实Read Uncommitted和Read Committed是一样的。
关于Repeated Read,因为在同一个事务内查询到的数据都是在开启事务后第一次查询时候的快照,可知在业务层开启事务后,事务内所有的乐观锁机制都将失效,毕竟都读不到其他事务的提交了,一定会造成写冲突。除此之外,看了不少的讲pg的事务隔离的文章,都是说pg的Repeated Read不会出现幻读…然后实际上,自测发现并不能完全避免。因为幻读其实分为好多种,在《A Critique of ANSI SQL Isolation Levels》论文就定义了好多种的幻读。可以说,pg的Repeated Read基于其MVCC的实现可以避免一部分,但是是无法完全避免的。
关于Serializable,pg在9.1之前,是没有Repeated Read这个隔离级别,只有Serializable。9.1之后,才把之前的Serializable重命名为Repeated Read,然后加上一个更为严格的Serializable隔离级别。在这两个隔离级别下,如果两个不同事务中同时修改一条记录都会导致其中某个事物写失败,所以在应用层需要有重试机制。
关于两者的不同,应该是说Serializable这种隔离级别可以解决更多的幻读问题,Serializable使用谓词锁(Predicate Lock)来防止这些幻读,意思是如果一个事务T1正在执行一个查询,该查询的的WHERE子句存在一个条件表达式E1,同时这个查询下面还有其他更新或者插入操作,那么另外一个事务T2 就不能插入或删除任何满足E1的数据行。比如之前遇到的并发问题,其实可以简单表达为(伪代码):
if not Binding.objects.filter(sku_code='test').all():
# 这里只有用all()才能触发pg的谓词锁,first(),exist()都不行
Binding.objects.create(sku_code='test')
如果是在Repeated Read下,可能就重复创建两条sku_code=‘test’的Binding了,但是在Serializable里面因为存在读写依赖,并发两条事务中肯定会又一条会失败,会提示’could not serialize access due to read/write dependencies among transactions’错误
MVCC常用实现方法
对于以上的事物隔离级别数据库应该怎么来实现呢。早期有通过用复杂的锁来实现的,最终也只是实现一部分,无法避免所有的并发问题,而且用锁来实现,会影响数据库的并发性能。对如今大部分的主流数据库,都是使用 MVCC(Multi-Version Concurrency Control)多版本并发控制来实现,达到并发并能和隔离性的完美平衡。 MVCC的基本思想是写数据时,旧的数据作为旧版本并不删除,并发的读还能读到旧版本的数据,这样读和写就可以并发了。一般MVCC有2种实现方法:
- 写新数据时,把旧数据转移到一个单独的地方,如回滚段(undo log)中,其他人读数据时,从回滚段中把旧的数据读出来,如Oracle数据库和MySQL中的innodb引擎。
- 写新数据时,旧数据不删除,而是把新数据插入。PostgreSQL就是使用的这种实现方法。
两种方法各有利弊,相对于第一种来说,PostgreSQL的MVCC实现方式优势在于:
- 无论事务进行了多少操作,事务回滚可以立即完成
- 数据可以进行很多更新,不必像Oracle和MySQL的Innodb引擎那样需要经常保证回滚段不会被用完,也不会像oracle数据库那样经常遇到“ORA-1555”错误的困扰
相比InnoDB和Oracle,PostgreSQL的MVCC缺点在于:
- 旧版本的数据需要清理。当然,PostgreSQL 9.x版本中已经增加了自动清理的辅助进程来定期清理(VACCUM)
- 旧版本的数据可能会导致查询需要扫描的数据块增多,从而导致查询变慢
PostgreSQL的MVCC实现
PG为了实现MVCC,表上面会有一些系统的隐藏字段(InnoDB类似),在每个tuple(其他数据库的Row)上,会有t_xmin,t_xmax,cmin和cmax,ctid,t_infomask这些字段。其中:
- t_xmin:存储的是产生这个元组的事务ID,可能是insert或者update语句
- t_xmax:存储的是删除或者锁定这个元组的事务ID
- t_cid:包含cmin和cmax两个字段,分别存储创建这个元组的Command ID和删除这个元组的Command ID(为了标志同一个事物内语句的先后顺序)
- t_ctid存储用来记录当前元组或新元组的物理位置
- 由块号和块内偏移组成
- 如果这个元组被更新,则该字段指向更新后的新元组
- 这个字段指向自己,且后面t_heap中的xmax字段为空,就说明该元组为最新版本
- t_infomask存储元组的xmin和xmax事务状态,t_infomask只有16位,所以最多存储16种独立的状态标志,以下是t_infomask每位分别代表的含义:
#define HEAP_HASNULL 0x0001 /* has null attribute(s) */
#define HEAP_HASVARWIDTH 0x0002 /* has variable-width attribute(s) 有可变参数 */
#define HEAP_HASEXTERNAL 0x0004 /* has external stored attribute(s) */
#define HEAP_HASOID 0x0008 /* has an object-id field */
#define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* xmax is a key-shared locker */
#define HEAP_COMBOCID 0x0020 /* t_cid is a combo cid */
#define HEAP_XMAX_EXCL_LOCK 0x0040 /* xmax is exclusive locker */
#define HEAP_XMAX_LOCK_ONLY 0x0080 /* xmax, if valid, is only a locker */
/* xmax is a shared locker */
#define HEAP_XMAX_SHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_LOCK_MASK (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | \
HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed 即xmin已经提交*/
#define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */
#define HEAP_XMIN_FROZEN (HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID)
#define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax committed即xmax已经提交*/
#define HEAP_XMAX_INVALID 0x0800 /* t_xmax invalid/aborted */
#define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax is a MultiXactId */
#define HEAP_UPDATED 0x2000 /* this is UPDATEd version of row */
#define HEAP_MOVED_OFF 0x4000 /* moved to another place by pre-9.0 * VACUUM FULL; kept for binary * upgrade support */
#define HEAP_MOVED_IN 0x8000 /* moved from another place by pre-9.0 * VACUUM FULL; kept for binary * upgrade support */
#define HEAP_MOVED (HEAP_MOVED_OFF | HEAP_MOVED_IN)
#define HEAP_XACT_MASK 0xFFF0 /* visibility-related bits */
同时,每个事务都有自己的id,事务id是一个32位的无符号整数。有3个特殊的事务id。
- 0代表invalid事务号,无效的事务ID
- 1代表bootstrap事务号,系统表初始化的事务ID
- 2代表frozon事务。frozon transaction id比任何事务都要老
可用的有效最小事务ID为3,然后开始递增。同时,事务的状态会保存在Commit log里面,简称clog,事务状态有以下4种:0x00:表示事务正在进行,0x01:事务已提交,0x02:事务已回滚,0x03:子事务已提交。
这些隐藏字段具体到每个操作的变化:
- 插入数据的时候,插入的tuple的t_xmin就是当前的事务id,t_xmax为0,t_ctid保存的是当前tuple的物理位置,t_infomask为HEAP_XMAX_INVALID。如果提交,则t_infomask增加HEAP_XMIN_COMMITTED标志位,如果回滚,则t_infomask增加HEAP_XMIN_INVALID标志位。
- 删除数据的时候,删除的tuple的t_xmax为当前事务ID,t_infomask去掉HEAP_XMAX_INVALID,说明此时t_xmax有效。如果提交,t_infomask加上HEAP_XMAX_COMMITTED,删除有效。如果回滚,则又加上HEAP_XMAX_INVALID,说明这个删除事务无效,但是t_xmax还是当前事务id,这里主要基于性能考虑,可以直接考t_infomask来判断事务状态即可,没必要再把t_xmax刷回0。
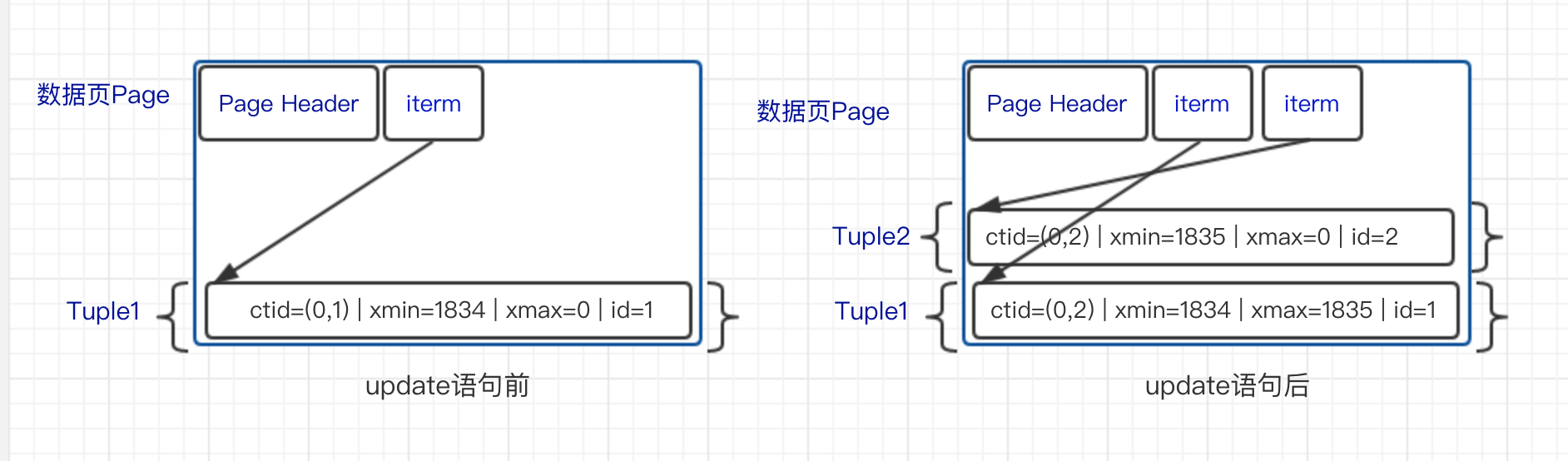
- 更新数据的时候,会产生一个新的tuple,同时把那个旧tuple的t_xmax改为当前操作的事务ID,t_ctid改为新tuple的t_ctid,同时把旧的t_infomask加上已冻结状态:HEAP_XMIN_FROZEN(HEAP_XMIN_COMMITTED | HEAP_XMIN_INVALID)。新tuple类似insert的结果,不同的是t_infomask多了个HEAP_UPDATED状态,它的含义是这个版本是由update产生的。如下图: {% asset_img 1.png %}
可见性规则
那怎么判断一个tuple当前事务是否可见呢?tuple对于当前事务的可见性受生成它的事务(t_xmin)的状态、更新它的事务(t_xmax)的状态、当前事务的隔离级别和事务快照(Snapshot)共同影响。
通过SELECT txid_current_snapshot()可以查看当前的事务快照,里面主要包含三个字段:xmin、xmax、xip
- xmin:当前未完结(提交或回滚)并活跃的事务中最小的XID
- xmax:所有已完结事务(提交或回滚)中最大的XID,加1后记录在xmax中(比当前所有已提交的事务id都大)
- xip:当前所有的未完结并活跃的事务的数组
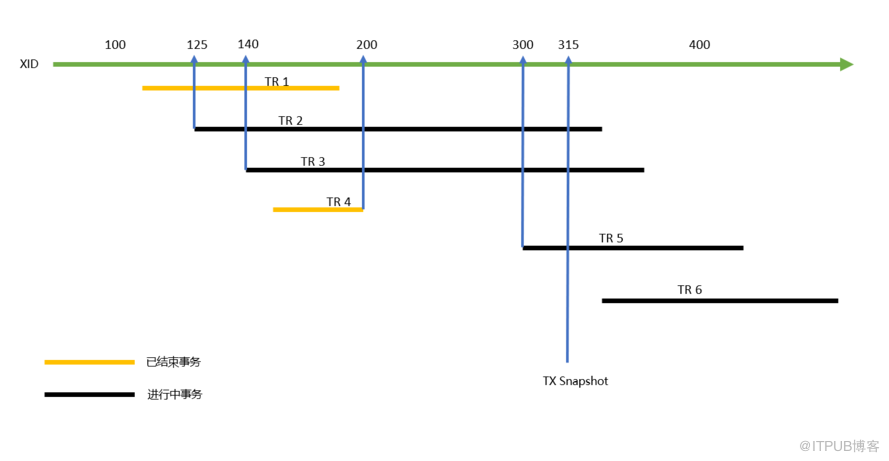
如上图,当前的事务id为315,获取此时的快照,其中xmin为125,xmax为201(200+1),所以此时的snapshot = 125 : 201 : 140。
事务ID小于xmin的事务表示已经被完结,其涉及的修改对当前快照可见;事务ID大于或等于xmax的事务表示正在执行,其所做的修改对当前快照不可见。事务ID处在 [xmin, xmax)区间的事务,已经完结的对当前事务可见,否则不可见。具体到其涉及的每个tuple,需要结合活跃事务列表与事务提交日志CLOG,判断其所作的修改对当前快照是否可见:
生成它的事务已提交,且尚未被其他事务修改或锁定的tuple可见。此时t_xmax = 0,且t_infomask为HEAP_XMIN_COMMITTED | HEAP_XMAX_INVALID
修改它的事务已中止的tuple可见。此时t_xmax != 0,且t_infomask为HEAP_XMAX_INVALID。
被其他事务正在修改的已冻结的tuple可见。此时t_xmax != 0,且xmax对应的事务状态为进行中,且t_infomask为HEAP_XMIN_FROZEN(HEAP_XMIN_COMMITTED | HEAP_XMIN_INVALID)。
由当前事务生成的,且尚未被当前事务修改的tuple可见。此时t_xmin为当前事务,t_xmax=0,t_infomask为HEAP_XMAX_INVALID
已经被其他事务修改,且该事务已提交的tuple不可见。此时t_xmax != 0,t_xmax不为当前事务id,且t_infomask为HEAP_XMAX_COMMITTED
生成它的事务已中止的tuple不可见。即t_xmin不为当前事务id,且t_infomask为HEAP_XMIN_INVALID,且没有HEAP_XMIN_COMMITTED。
被当前事务修改的tuple不可见。此时t_xmax为当前事务。
以上列出的判断规则其实主要还是为了保证只看到已经完结的事务(避免脏读)。因为没有看源码中的方法,来源都是实际实验中测出来的或者其他文章的总结,不能保证一定全,只是用来帮助理解,更深入的可以查看源码或者《PostgreSQL数据库内核分析》 因为更新的时候,会把原版本的t_ctid指向新的tuple,这样就从旧到新形成了一条版本链(InnoDB类似,不过是从新到旧)。不过需要注意的是,更新操作可能会使表的每个索引也产生新版本的索引记录,即对一条元组的每个版本都有对应版本的索引记录,即对一条元组的每个版本都有对应版本的索引记录。这样带来的问题就是浪费了存储空间,旧版本占用的空间只有在进行VACCUM时才能被回收,增加了数据库的负担。为了减缓更新索引带来的影响,8.3之后开始使用HOT机制。定义符合下面条件的为HOT元组:
- 索引属性没有被修改
- 更新的元组新旧版本在同一个page中,其中新的被称为HOT元组
更新一条HOT元组不需要引入新版本的索引,当通过索引获取元组时首先会找到最旧的元组,然后通过元组的版本链找到HOT元组。这样HOT机制让拥有相同索引键值的不同版本元组共用一个索引记录,减少了索引的不必要更新。
隔离级别的实现
了解了MVCC原理,那PostgreSQL是怎么实现事务隔离级别呢,在这点上,其实InnoDB也类似,都是根据获取快照的时机不同,实现不同的隔离级别:
- 读未提交/读已提交:事务重每个query都会获取最新的快照
- 重复读:事务中只有开始的第一个query会获取快照,后面的都以这个快照为基础,不再重复获取快照
- 串行读:使用锁系统来实现(SSI)
总结
对比InnoDB,PG的MVCC实现方法有利有弊。其中最直接的问题就是表膨胀,为了解决这个问题引入了AutoVacuum自动清理辅助进程,将MVCC带来的垃圾数据定期清理。PG的回滚可以立即完成,但是InnoDB需要回退undo log中的数据。另一方面判断可见性PG更复杂,开销更大,pg还需要访问clog来判断事务状态,底层也因为采用了堆存储数据而不是聚集索引来组织数据导致VACUUM回收的时候可能会产生碎片。不过对比Serializable级别的实现,PG貌似更先进些,这部分还了解的不是很清楚,留个坑后面再详解
参考链接
- https://peter.grman.at/postgres-repeatable-read-vs-serializable/
- https://www.wanghengbin.com/2018/03/29/postgresql-mvcc-lock/
- http://www.cnblogs.com/dhcn/p/7120895.html
- http://blog.itpub.net/6906/viewspace-2562652/
- https://tech.meituan.com/2014/08/20/innodb-lock.html
- http://mysql.taobao.org/monthly/2017/10/01/
- https://blog.csdn.net/collin1211/article/details/6024691