怎么高效的调试python程序(1)
这篇文章是受到18年pycon上张翔大神演讲的启发,当时他的演讲的题目是《我的python进程怎么了》,主要是介绍了python进程调试的一些工具和方法,总结的比较全,当时在现场听完感觉受益匪浅,但是一直没去整理,这篇文章大致也是按照他的ppt的大纲来写的。
我们代码写完后,运行时经常会遇到这样那样的问题,有一些很容易就能发现,因为代码跑到这里就直接就报错了,抛异常了,一般看日志的报错信息就能发现具体是哪里出了问题。但是还有一部分是没法从日志中看出来的:“为什么我的python进程卡住了”,“为什么我的python进程消耗这么多的内存”,“为什么我的python进程消耗了这么多的cpu”,卡住了是因为死锁了还是阻塞在io上了?消耗内存多了是因为存在内存泄漏还是数据结构设计的不合理?这种时候就需要一系列的工具来排查,工欲善其事,必先利其器。
print&log
相信对大部分人来说,print和log是最常用的调试方法了。在感觉有问题的地方,加上print和log来输出一些状态信息和变量,每个python程序员都是这方面的大师。
print&log大法简单粗暴,但往往很有效。缺点是需要提前了解你的代码,知道在哪里print&log,而且需要修改后重启你的进程,调试完还要删除调试的代码。
pdb
pdb是python自带的一个库,为python程序提供了一种交互的源代码调试功能,主要特性包括设置断点、单步调试、进入函数调试、查看当前代码、查看栈片段、动态改变变量的值等。pdb可以认为是python下的gdb,两者保持了一样的用法。
有两种不同的方法使用pdb,一种是直接在命令行指定参数启动pdb,比如直接python -m pdb pdb_test.py 可以进入命令行调试模式,接下来可以输入相应的调试命令进行调试,比如:l是查看当前代码,b是设置断点,n是执行下一行,单步调试。输入h可以查看各命令的使用说明。
pdb单步执行太麻烦了,第二种方法是直接在代码中import pdb,直接在代码里需要调试的地方放一个 pdb.set_trace() 设置一个断点,程序运行到这里会暂停并进入pdb调试环境,可以用pdb 变量名查看变量,或者c继续运行。关于pdb更详细的使用方法,可以查看官方文档
但是实际工作中,很多时候我们都是使用flask或者django等框架来开发,特别是django,很多时候需要在django shell里面进行一系列的调试,这个时候pdb就不好启动了,可以使用django-pdb。
除了pdb,还有一个第三方的开源的python调试器Ipdb,具有语法高亮、tab补全,更友好的输出信息等高级功能,ipdb之于pdb,就相当于IPython之于Python,虽然都是实现相同的功能,但是,在易用性方面做了很多的改进。如果使用ide,比如PyCharm,很多都自带了断点设置,变量查看的功能,使用上更加方便友好。
sys
sys模块包括了一组非常实用的服务,内含很多函数方法和变量,用来处理Python运行时的配置以及资源,从而可以与当前程序之外的系统环境交互,是python程序用来请求解释器行为的接口。
很长一段时间里面,都不清楚sys模块的重要性,说这是python标准库中最重要的模块之一也不为过了,后来陆续接触到sys模块的一些黑科技般的方法,才逐渐的了解到它的强大,里面很多的方法涉及到的背景和知识都能另起一篇文章了,所以这里只介绍一部分。
sys._getframe([depth]): 返回一个栈帧对象,depth为栈顶部向下的深度,默认为0,返回的是当前的栈帧。
>>> import sys
>>> frame = sys._getframe()
>>> dir(frame)
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__',
'__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__',
'__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__',
'__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'clear', 'f_back',
'f_builtins', 'f_code', 'f_globals', 'f_lasti', 'f_lineno', 'f_locals', 'f_trace']
>>> assert frame.f_back == None
>>>
>>> dir(frame.f_code)
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__',
'__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__',
'__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__',
'__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'co_argcount',
'co_cellvars', 'co_code', 'co_consts', 'co_filename', 'co_firstlineno', 'co_flags',
'co_freevars', 'co_kwonlyargcount', 'co_lnotab', 'co_name', 'co_names',
'co_nlocals', 'co_stacksize', 'co_varnames']
>>> frame.f_code.co_name
'<module>'
frame.f_back返回上一个栈帧对象,也就是调用栈的上一层,这里因为是直接在python shell中使用的,调用栈就一层,所以frame.f_back返回None。其他的,比如f_locals返回当前栈帧的本地变量,f_globals返回全局变量。通过f_code可以获得PyCodeObject。这个对象保存了栈帧引用的代码块的一些信息,比如函数名称co_name,这里因为已经是栈底了,所以frame.f_code.co_name显示的是<module>。所以可以通过这些方法写一个函数,可以获取这个函数调用者的一些信息:
def func():
frame = sys._getframe(1)
code = frame.f_code
caller_msg = f'func called by {code.co_name} in file: {code.co_filename} {frame.f_lineno} line'
print(caller_msg)
sys._current_frames(): 返回函数调用时,每个线程标识符与顶层堆栈帧的字典映射,这里只有一个线程,所以字典只有一项:
>>> sys._current_frames()
{140736139600768: <frame object at 0x106484528>}
sys.getswitchinterval():返回解释器的“线程切换间隔”,也就是多线程下一个线程执行多久会被gil切换。
sys.getrecursionlimit(): 获取最大递归的层数
sys.getrefcount(object):返回对象的引用计数,执行的时候已经又被引用了一次,所以真实的引用次数应该-1
sys.getallocatedblocks():返回解释器当前分配的内存块数量。主要用于追踪和调试内存泄漏。受解释器内部缓存影响,每次调用返回的值都可能不一样,可以通过调用_clear_type_cache()和gc.collect()方法获取更可预测的结果。
这里重点介绍了sys._getframe方法,因为之前就做过一个这样的需求,要在一个log工具类中打印出调用这个类的调用者的信息,所以印象很深刻。但是官方文档不建议通过这种方式获取当前栈帧,官方文档并不保证在Python的所有实现中都存在这个方法,建议使用inspect.currentframe()获取当前栈帧。
除了上面这些,sys里面还有很多强大的工具,更详细的可以看看官方文档
profile
如果我们的进程有大量的计算,又没有对应的输出信息,可能会让我们误以为卡住了,又或者我们需要对性能进行调优,我们需要一些工具来进行性能分析。python官方库有两个很方便的工具:Profile和cProfile(还有个hotshot,但是已经不维护了,所以忽略)。
这两者的使用方法完全一样,不同的是cProfile是c实现的,运行开销比较小,适合分析运行时间比较长的项目,是我们大部分情况下的首选。Profile是一个纯python的模块,运行开销比较大,如果想扩展其他的功能的话,可以继承这个模块。
提到cProfile,就不得不提pstats,这个模块是用来处理cProfile的分析结果。有两种方法使用cProfile,一种是在命令行里使用python3 -m cProfile profile_test.py,可以得到整个profile_test.py程序运行的分析结果,或者直接在程序内使用,举个栗子:
from cProfile import Profile
import pstats
def foo1():
return foo2() * 3
def foo2():
return foo3() * 2
def foo3():
# "this call tree seems ugly, but it always happen"
return 1
def flat_foo():
return 1 * 2 * 3
def flat_foo2():
a = 1
b = 2
c = 3
return a * b * c
def calculate1():
sum = []
for i in range(10000):
sum += [i * i * i]
def calculate2():
sum = []
for i in range(10000):
sum = sum + [i * i * i]
def main():
for i in range(100000):
if i % 10000 == 0:
calculate1()
elif i % 10000 == 1:
calculate2()
elif i % 3 == 1:
flat_foo()
elif i % 3 == 2:
flat_foo2()
else:
foo1()
if __name__ == '__main__':
prof = Profile()
prof.runcall(main)
ps = pstats.Stats(prof)
ps.strip_dirs().sort_stats("tottime").print_stats()
脚本引入Profile类,分析main的执行情况,收集到性能分析的数据后,通过pstats的Stats来进行排序并输出到终端:
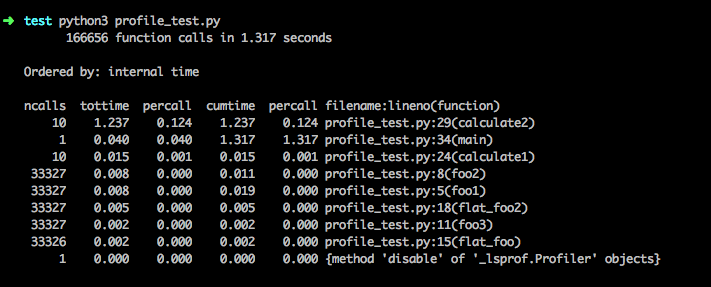
对于上面的的输出,每一个字段意义如下:
- ncalls 函数总的调用次数
- tottime 函数内部(不包括子函数)的占用时间
- percall(第一个) tottime/ncalls
- cumtime 函数包括子函数所占用的时间
- percall(第二个)cumtime/ncalls.
- filename:lineno(function) 文件:行号(函数)
分析下这个结果,我们会发现一些有意思的事情。执行时间最长的是calculate1,对比下calculate2发现两者的差异只是一个使用+=操作,一个是直接+的操作,因为列表是可变对象,python对可变对象的+=操作是直接在这个可变对象原分配的内存块上进行,而每次+操作的结果都会重新分配一块内存,无形中降低了效率,这部分性能损耗还是挺大的,可以看到速度相差了100多倍。接下里是foo1,foo1其实只是做了一个1*2*3的操作,但是确需要调用3层的函数来计算,flat_foo和flat_foo2只有1层,说明了调用栈频繁的生成和销毁其实是有一定的运行开销的。那为什么flat_foo和flat_foo2的运行时间也不一样呢,因为python解释器会进行一系列优化,比如对于1 * 2 * 3这种表达式会进行常量替换,直接替换成6,这样就不用每次都计算了,但是对于a * b * c解释器就没法进行替换了,因为python是动态语言,没法进行静态分析,abc的值只有在运行时才能确定。
除了直接在终端展示,我们还可以保存cProfile分析的结果。可以在运行时指定,比如python3 -m cProfile profile_test.py -o result,或者在程序里面prof.dump_stats('result')。保存下来的结果可以用一些图形化的工具进行分析,比如visualpytune、qcachegrind、runsnakerun等。
其他
本来打算一口气把演讲中提到的所有调试工具和方法都写完的,但是真正写的时候发现每个工具都能牵扯出很多的东西。而自己水平也有限,不敢随便就下笔写,只能查阅确认后再写,所以很耗费精力,最后还是打算分成几个部分来写了,加油吧
参考链接
https://www.ibm.com/developerworks/cn/linux/l-cn-pythondebugger/index.html
https://zhuanlan.zhihu.com/p/25942045
https://docs.python.org/3/library/inspect.html
https://docs.python.org/3.6/library/sys.html
http://www.cnblogs.com/xybaby/p/6510941.html
https://zhuanlan.zhihu.com/p/24495603